

生成AIが流行っているらしい。でも非プログラマ属性の方々(筆者も)は、せいぜいChatGPTのブラウザ版を無料の範囲でちょっと触ってみるくらいなのでは?
ですが、ゲーミングPCを持ってるならちょっと話は変わってきます。無料でPCにChatGPT(みたいなAI)を入れて、料金も情報漏洩も気にせずに、好き勝手に使い放題することが出来るんです。
ということで、ここでは非プログラマ属性の筆者がローカルPCにGoogle製LLMのGemma3をインストールする方法を解説します。超初心者向けです。ちなみにストレージ容量は5GBも使いません。

chatGPTとローカルLLMの違い
『生成AI』とザックリ言ってますが、ここで扱うのはLLM(大規模言語モデル)と呼ばれるAIを指します。LLM(大規模言語モデル)とは、”過去のいろんな知識を持っていてチャットでやり取り出来てたまに嘘をつく「言葉を操る生成AI」”です(たぶん)。
で、ChatGPTに代表されるクラウドベースのLLMサービスと、今回導入してみるローカルLLMの違いはこんな感じです。
| 特徴 | クラウドベースLLM | ローカルLLM |
|---|---|---|
| 仕組み | サーバー上で動作 | PC上で動作 |
| 利用方法 | ウェブサイト/API | ダウンロード・インストール |
| 利用料金 | 月額課金制が多い | 無料 |
| 性能 | 高い | 低い (モデルによる)※1 |
| プライバシー | 低い | 高い |
| オフライン利用 | 不可 | 可能 |
| カスタマイズ性 | 限定的 | 高い |
| ハードウェア要件 | なし | 高い (GPU推奨)※2 |
利用料金を気にしない方、LLMの維持管理に手間を割きたくない方、常に最新最先端で勝負する方はクラウドベース。
自分で学習させてカスタマイズしてカリッカリで使いたいプロの方はローカルLLM。
ついでに、逆に最新じゃなくてもいいから料金を気にせずにいろいろ触ってみたい趣味&初心者の方にもローカルLLMは面白いんじゃないかと思います。とりあえず触ってみて、そのうちある程度使えるようになってればいいな、くらいの気概があればチャレンジの価値アリ。
※1
クラウドベースの最新モデルに比べるとローカルLLMは性能的に劣る傾向にありますが、2024年後半あたりからはローカルLLMといえども実用に耐え得る高性能モデルが続々リリースされている。と詳しい方々がおっしゃってます。
※2
ローカルLLMはPCスペックが高くないと導入できません。そして、ゲーミングPCって一般的なPCと比べるとかなり高性能なんです。具体的にはRTX3060程度のグラボが搭載されていれば動きます。ということは、初期費用ゼロでAIが使い放題なんです。と言っておられる記事が多数あります。(筆者は4070)
ローカルLLM実行環境
ローカルLLMをPC上で実行するには、実行環境ソフトウェアが必要になります(フレームワークと呼んだりもするみたいです)。これをゲーマーに例えると、ゲームを遊ぶためにSteamを入れる、みたいなことでしょうか。
で、調べるとだいたい出てくるのが『LM Studio』や『Ollama』といった有名どころ。当然どちらも無料です。※一部有料の機能もあるみたいです。
そして両者のもっとも大きな違いはインターフェースです。
| 特徴 | LM Studio | Ollama |
|---|---|---|
| インターフェース | GUI | コマンドライン |
GUI(グラフィカルユーザーインターフェース)とは、直感的に見て操作できる図形やボタンなどを使用したインターフェース。
コマンドラインとは、コマンドプロンプトなどに代表される文字列コマンドだけで繰り広げられる黒魔法の世界。
ここでは筆者を含め【超初心者向け】の解説をしているので、おすすめはLM Studioとなります。
※OllamaにUIソフトウェアをくっつけて使うことも出来ますが、1ストップで済むLM Studioがおすすめ。
ローカルLLMおすすめモデル
ローカルLLMとして使用できるモデルは複数あります。記事執筆時点で代表的ものを何点か挙げます。
| model名 | 開発元 |
|---|---|
| Gemma3 | |
| Qwen3 | アリババ |
| DeepSeek R1 | DeepSeek |
| Phi-4 | Microsoft |
| Llama3 | Meta |
どれも無料のオープンソースモデルで、どれも超初心者から見ればすごくちゃんとしたAI(LLM)です。そのうえで、細かい性能や特徴のことをあーだこーだ言ってもどーせよくわからないと思うので、まずは開発元の名前と印象で選んでも良いと思います。
オープンソース=中身まで公開されていて誰でもチェックできるソフトウェアなので、基本的にはどれも一定程度は安全だと思って良いでしょう。中国製だから怖い、危ないといったことも基本的にはありません。
筆者は何かと馴染み深いGoogleのGemma3を選択。Geminiの兄弟分のような生い立ちのLLMです。
ローカルLLMインストール手順
まずはじめに、筆者のPCスペックは以下。
- OS…Windows11
- CPU…AMD Ryzen7 5800X3D
- GPU…NVIDIA GeForce RTX4070
- メモリ…64GB
- ストレージ…C:ドライブに最低10GBくらい空いてればたぶんOK
LM Studioをインストール
まずは実行環境としてLM Studioをインストールします。公式サイトはこちら。
特に難しいことは無いのでサイトに従って進めてください。
Gemma3をインストール
Gemma3をインストールします。工程はLM Studio上の操作で完結します。
まず、LM Studioをインストールして立ち上がる画面↓。
「さぁ、最初のLLMを手に入れよう!」ということで「Get your first LLM」をクリック。
次におすすめのLLMをゴリ押ししてきます↓。
なぜかDeepSeekをおすすめされてますが、個人的に中国製は…なのでスルーしたい。が、どこに進めばいいかわかりづらいので注意してください。
画面右上の端っこに小さく「Skip onboarding→」の表記があるのでクリック。
すると、LM Studioのメイン画面へ移動します↓。
ここではLLMを検索したいので、左端の『🔎』マークをクリック。
インストール可能なLLMがたくさん出てくるので、目当てのモデルを選んでください。
なおGemma3には1B,4B,12B,27B,さらにそれぞれのQATモデルがあります。計8モデル。
※2025年5月時点の状況です。
『〇B』というのはAIのパラメーター数(1ビリオン=10億)を指し、ざっくり言えば数字が大きいほど高性能です。ただしパラメータ―数が大きいほど処理が重くなる(処理が複雑になる)ので、動きの軽快さとはトレードオフの関係にあることに注意してください。
1Bは明確に機能が少ないので、おすすめは4Bか12B。ここでGPUのメモリなども関わってくるので詳しくはググってほしいんですが、超初心者向けとしてまずは4Bで良いと思います。RTX3060でももちろん動きます。
さらに『QAT(Quantized Adaptive Transformer)』は”パラメーターの量子化”と呼ばれる軽量化などを施したモデルで、モデルサイズの削減や電力消費の削減をした計量モデルです。
筆者は「Gemma3 4B QAT」を選択しましたが、無料で何個でもインストールして試せるのであまり悩まずにとりあえず入れてみる感じで良いと思います。
で、選択したLLMをインストールすると↓
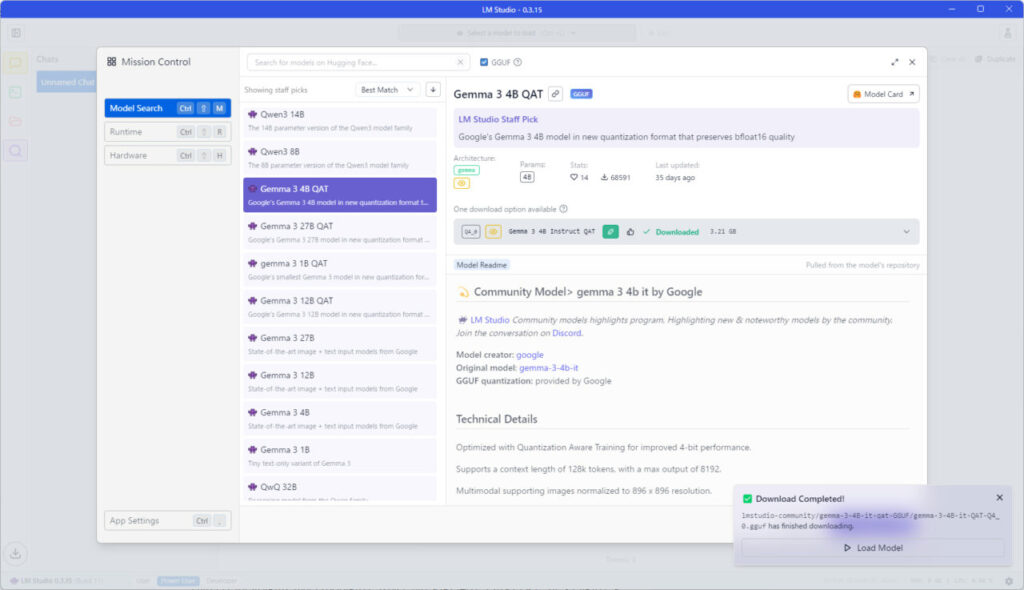
画面右下に「Download Completed!」の表示が出現。「▷Load Model」をクリックすると、ついにローカルLLMを使用することが可能になります。
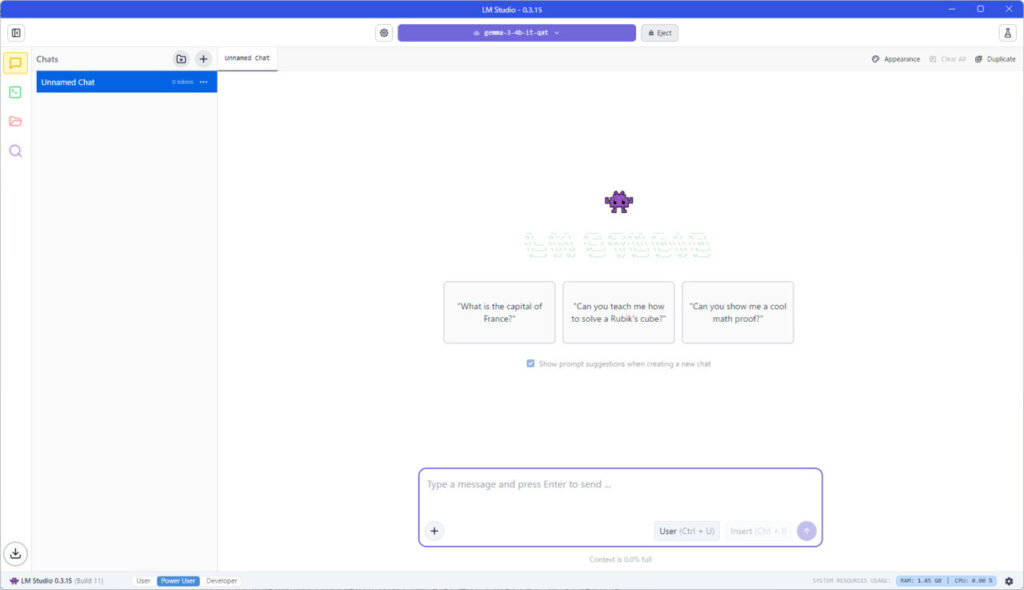
画面構成はChatGPTとほぼ同じ。一応画面中央上部に選択したLLMが表示されていることを確認してください。
これで一連のインストールは終了です。とても簡単でした。
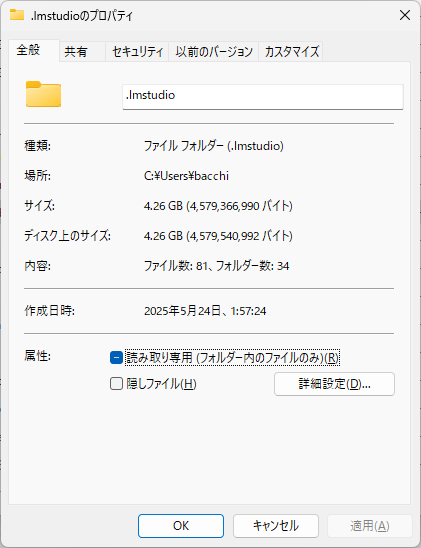
LM StudioとGemma3 4B QATを足しても容量は4.26GB。AIって軽いんですね。
性能はボチボチ 使い道はいろいろ
何を何回聞いても無料なので、とりあえずなんでも試してみてください。
お悩み相談するもよし。恋愛相談するもよし。
コードを書かせてツールを作るもよし。WEBサイトをイチから作ることも可能です。
なお筆者はwebサイトやツールなどのコーディングをメインに使用していますが、性能としてはまだちょっと…。
何度聞いて修正しても正しく動かず、数時間ハマったあとにクラウドベースのgithub copilotに聞いたら一発解決、みたいなことが結構あります。
PCのスペックを上げてパラメーター数の大きいモデルを使用すれば改善する可能性もありますが、どーしてもという時はやはり有料のクラウドベースが優秀なようです。